Scraping the entire louvre library in one line of code
A couple of days ago, I came across this hackernews post. What an amazing news! The entire collection of Louvre has been made public here. I attempt to download the entire library. Took a short screencast as I began this download. Recoded & Annotated with Camtasia.
Lets get started!
For a while, I was meaning to download some classical paintings in bulk to create a live version of ClassicalArtMemes. It will be ideated using Django, Tailwind and Vanilla JS. And Louvre making all its artwork public was a perfect way to gather seed data I’ll later need for my webapp.
Step 1 : Figuring out the website
Any time I have a huge data collection job(for myself or a client), I like to begin with closely observing the website in question. While my scraping/automation/data-collection toolbelt consists of Python, Scrapy, Selenium, Puppeteer, lxml/Beautifulsoup, sometimes that is a clear overkill. Noticing the website and its quirks can reduce the amount of effort significantly. It’s kind of akeen to a much more plebian version of reverse-engineering.

As you can see, there are all sorts of work of arts. Let us check the painting section, and then open one of the paintings.
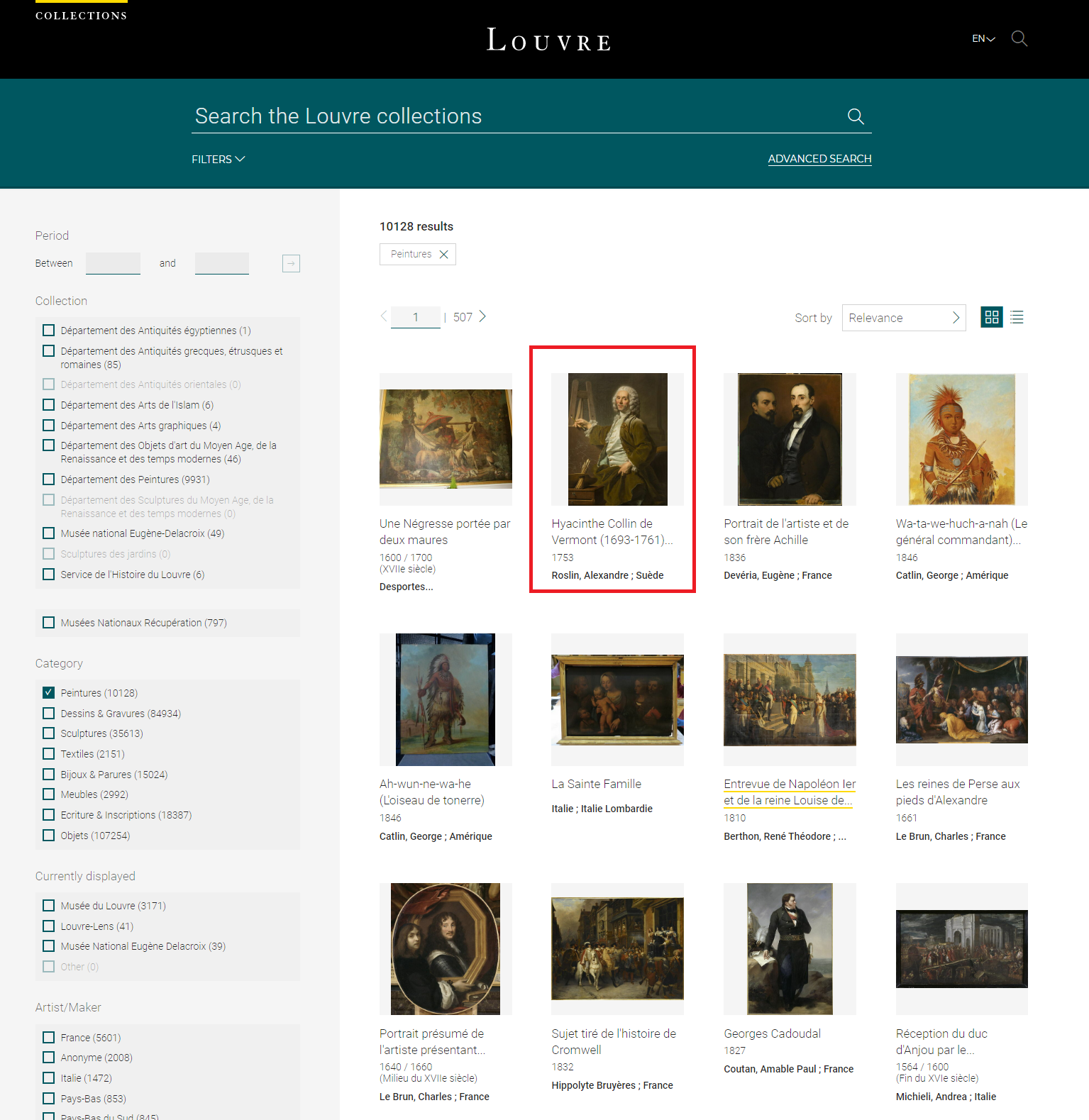
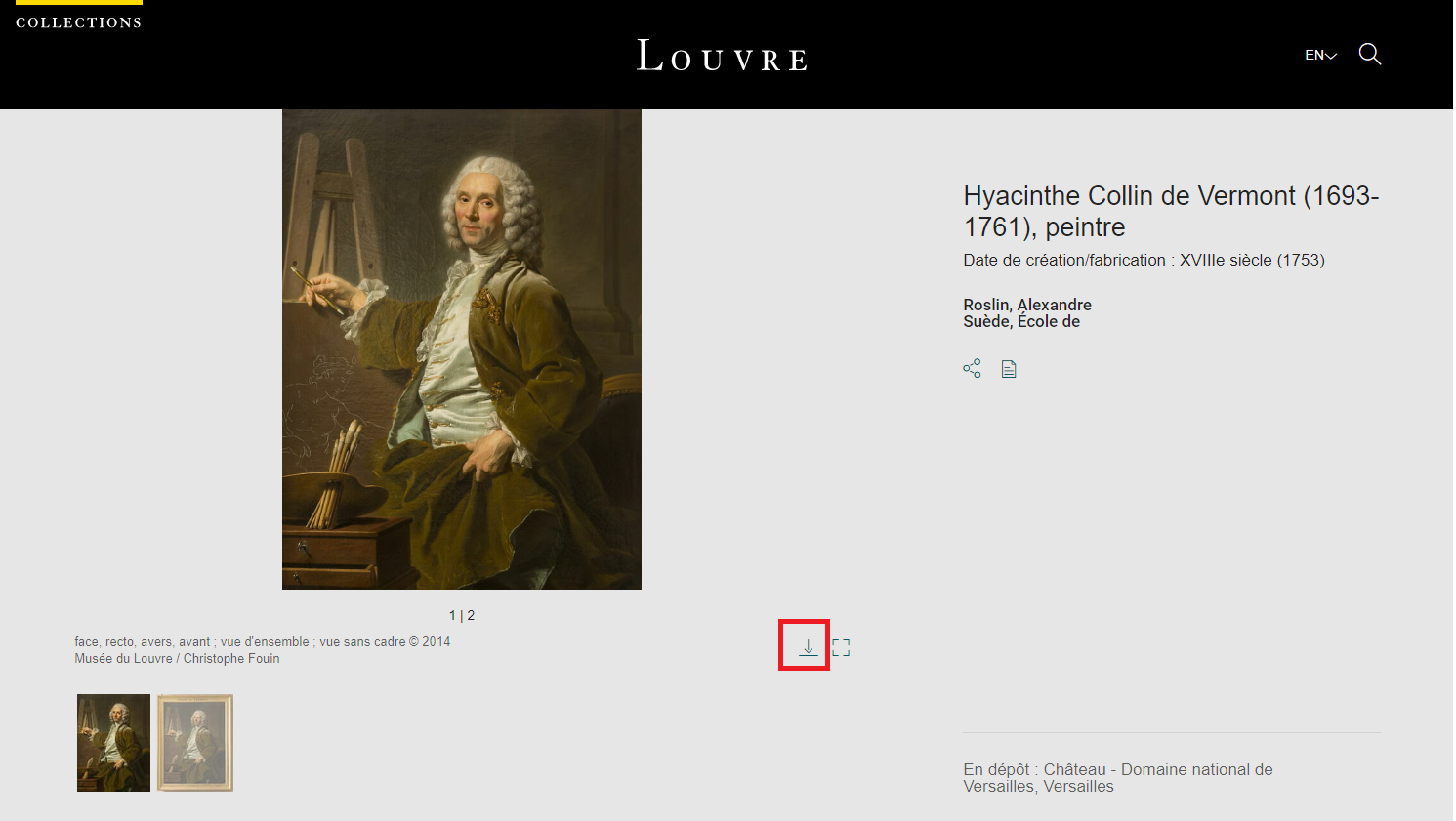
It looks like the detail page of the painting consits of photos in various angles. It also presents us with a download button. Lets click that

Interesting! So in order to download this gallery(zipped file containing images) I’ll have to accept the TnC and then click download.

On clicking download, I’m presented a prompt to save the file on my host machine.
At this point, it is more than obvious to me that the common way to go about collecting data from the site is to
- Create a Scrapy Crawler with pagination support
- Automate the clicks from browser to accept TnC and download the zipped version of art gallery.
Step 2 : Finding an easier way out
Now that we have the usual method to go about crawling the site, let us dig in some more. If we’re lucky we might just end up with some url hack to make our lives easy.
Checking the download URL of the artwork, it seem to be following a pattern. It can easily be broken down to 3 parts

- the resource prefix: ‘https://collections.louvre.fr/en/artwork/image/download/’
- the paramter ie the zip file number(121146) consisting the artwork
- the suffix: ‘/0’
We have a theory but lets spot test this with another example. Without opening any other detail page, lets create our own URL as following
- the resource prefix: ‘https://collections.louvre.fr/en/artwork/image/download/’
- the paramter ie the zip file number(121147) consisting the artwork
- the suffix: ‘/0’
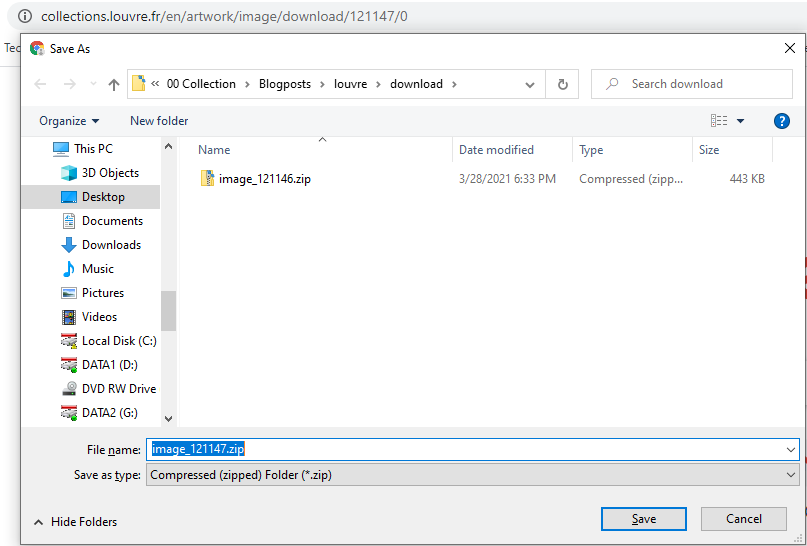
And now enter it into the browser.
Voila!! Our theory stood well. Althouh The Louvre is keeping it’s artwork behind a clever disguise of ‘download’ button and a ‘TnC’ modal, it is merely a collection of links hosted and served from the CDN.
Step 3 : Download Automation - The process for upper limit to try
Now that we have an in with a timid url hack, our job is to create the list of urls to. There are better methods here. I’ll use the most common one used by many scrapers.
It’s like trying a binary search over a large set of parameter numbers and finding and upper limit where we run into an error.
So we start with a range of 1 to 1,000,000. Try to see if there is a downloadable link present for the middle ie paramter=5,00,000. Nope! I ran into an error.
Now my range to try reduced from 1 to 500,000. I try to download for a parameter 250,000 and am able to download the zip file.
Now my range to try is from 250,000 to 500,000.
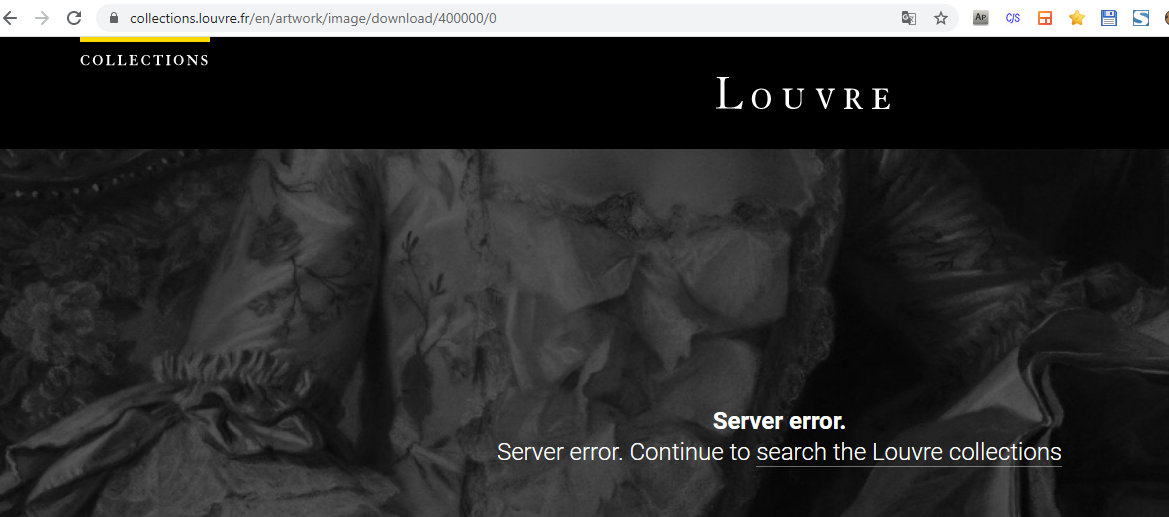
Well I tried a few more times like that and decide to go with an upper limit of 400,000 where I couldn’t dowload the file. I don’t care care if several links on the upper end of this spectrum don’t have download links, as the tool I used in next section can ignore those & just won’t download anything. Plus it runs pretty fast and parallelized, so I can get away with trying to find the exact number for my upper bound.
Step 3 : Download Automation - The right tool
Now I have a couple of jobs in front of me. Those can be broken down as:
- Creating a sequence of URLs I want to try downloading from 1 to 400,000(my supposed upper bound)
- Dowloading a URL and naming the corresponding zipped file
- A way to parallelize so I can try 100s of downloads at single instant of time. Essentially a 100X speedup against a normal sequential download over a list of given urls.
Every single one of these mini-tasks fall within the realm of Unix and it’s pipe-able philosophy. Time to whip out Ubuntu. There are number of ways to get the expected results(ie downloading entire Louvre library) here. But I’ll mention the three most relevant(that I felt & ended up using)in order below.
- Creating a sequence of URLs I want to try downloading from 1 to 400,000(my supposed upper bound) : SEQ
- Dowloading a URL and naming the corresponding zipped file: WGET
- A way to parallelize so I can try 100s of downloads at single instant of time. Essentially a 100X speedup against a normal sequential download over a list of given urls : GNU-PARALLEL
TLDR:
If you haven’t already dozed off in the build-up itself :) it’s time to create that single line of code/command
-
seq 400000 –> will create the needed sequence
-
parallel -j100 –> will parallize the job by downloading 100 tasks we are about to give
-
wget https://collections.louvre.fr/en/artwork/image/download/{}/0 -O {}.zip –> will download one zip file for every {number} in sequence and the downloaded file have the name as {number}.zip
Drumrollssss….
seq 400000 | parallel -j100 wget https://collections.louvre.fr/en/artwork/image/download/{}/0 -O {}.zip
That’s it!! That single line of code is going to download the entire Louvre library for us. As of writing this, I kept the script running for ~30 mins & it has already ploughed through the first 50,000 URLs(nearly 50GB of data). I reckon another couple of hours and I’ll have the entire Library in my hard-drive.
I took a small screencast as I began this download and it is hosted on youtube here. Recoded & Annotated with Camtasia.
Introspection:
-
As I look back, I think my hard-drive is whirring like it’s about to take off. Should have just spun up and EC2 instance on AWS, created and mounted an s3 bucket to that instance. I could have easily piped every single download directly to the S3 bucket without having to download it to my instance. So a beefy instance is not necessary for this I/O intensive job.
-
The Louvre needs to spend some time putting restriction in place when it comes to download limits. I’ve already downloaded 75GB data and the ‘429 too many requests’ is nowhere in sight. I’m not complaining, but someone in their IT department needs to monitor download traffic. Or it could just be that server costs are puny in their eyes considering the $$$ they rake in hosting arguably the best artwork in the world dating back to centuries.
That’s it for this job! Weekend afternoon well spent.